Research
Mathematical frameworks for machine learning; LiDAR/3D point clouds; numerical analysis, PDEs, and functional analysis
My research develops mathematically grounded tools for modern data problems, with a focus on building mathematical frameworks for machine learning. A recurring theme is designing representations and features that are both computationally effective and mathematically interpretable. This includes feature engineering inspired by measure theory and functional analysis, and dimensionality reduction methods (e.g., PCA and autoencoders) for high-dimensional and geometric data such as LiDAR/3D point clouds.
I also work in numerical analysis and partial differential equations (PDEs), including PDE-based models for physical phenomena in porous media and geoscience applications (e.g., methane hydrates and adsorption models).
Before focusing on machine learning and computational research, I worked in functional analysis, with particular emphasis on Banach space theory and Orlicz spaces. This early work played a central role in my decision to pursue a Ph.D. in mathematics. My broad background continues to shape how I approach research: I enjoy connecting ideas across areas—from pure mathematics to computation and real-world data.
Machine Learning for Geometric Data and Representation Learning
My recent research focuses on developing mathematically grounded approaches for machine learning on geometric and high-dimensional data. A recurring theme is the construction of informative representations that capture meaningful structure in complex datasets while remaining interpretable. This work combines ideas from machine learning, geometry, measure theory, and dimensionality reduction.
A central application area is 3D LiDAR point clouds. LiDAR data provide detailed geometric descriptions of natural and built environments and play an important role in applications such as forest monitoring, environmental assessment, terrain mapping, and urban analysis. The resulting datasets are often large, noisy, and highly structured, making representation and feature design critical components of successful learning pipelines.
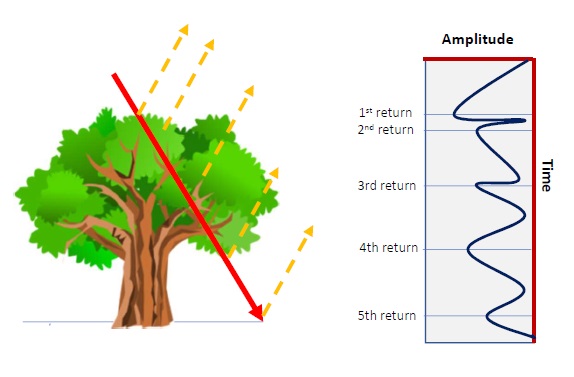
My work investigates how feature engineering, dimensionality reduction, and machine learning algorithms interact in the classification of LiDAR point clouds. In collaboration with colleagues at Worcester Polytechnic Institute, I have studied classification frameworks that combine local geometric information, engineered features, and learning models such as k-nearest neighbors, Random Forests, and neural-network-based methods.
One line of research explores the use of product coefficients, multiscale descriptors arising from measure-theoretic representations, as features for machine learning. Rather than introducing the coefficients themselves, my work investigates how they can be adapted to local neighborhoods in point-cloud data and incorporated into machine learning pipelines. These descriptors provide information about local geometric organization at multiple scales and complement traditional spatial attributes.
$$ a_S = \frac{\mu(L(S))-\mu(R(S))} {\mu(L(S))+\mu(R(S))} $$Here \(a_S\) denotes a product coefficient associated with a dyadic set \(S\), while \(L(S)\) and \(R(S)\) denote its dyadic children. Collections of such coefficients provide multiscale information about the distribution of mass within local neighborhoods and can be used as geometric descriptors for machine learning tasks.
A second line of work studies dimensionality reduction and representation learning. I have investigated both classical approaches such as Principal Component Analysis (PCA) and nonlinear methods based on autoencoders. Recent results suggest that combining product coefficients with learned latent representations can improve classification performance relative to using spatial coordinates alone or linear dimensionality reduction methods.
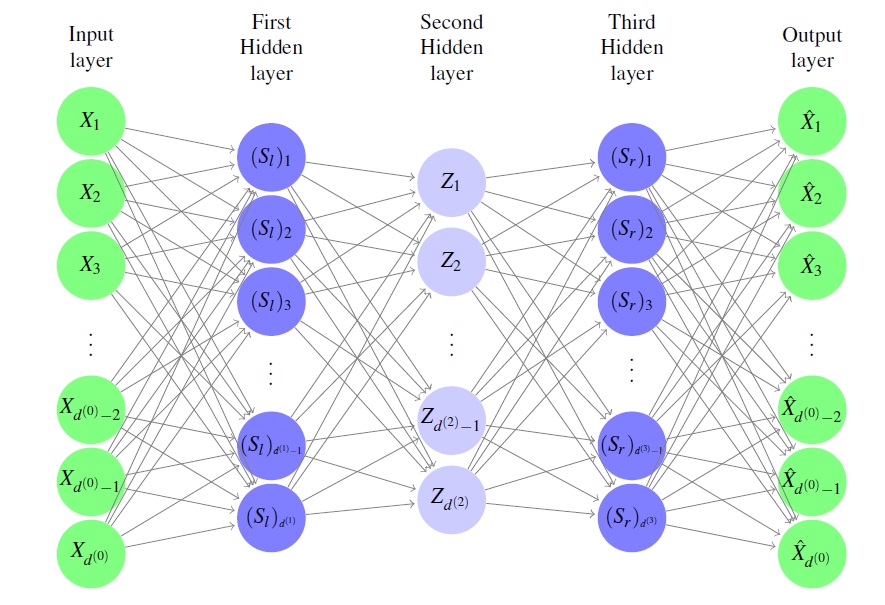
More broadly, I am interested in understanding how mathematically interpretable representations can complement modern machine learning methods. Current projects explore geometric feature extraction, representation learning, dynamical autoencoder architectures, and applications to LiDAR and other scientific datasets with complex multiscale structure.
Methane Hydrates and Phase Transitions in Porous Media

Methane Hydrates and Phase Transitions in Porous Media
My earlier research focused on mathematical models for methane hydrate formation and dissociation in porous media. Methane hydrates are ice-like crystalline structures that form under conditions of high pressure and low temperature and are of interest in both energy and environmental applications.
The mathematical models involve nonlinear partial differential equations with phase transitions and solubility constraints. A simplified formulation can be written as
$$ \frac{\partial u}{\partial t} -\nabla\cdot\big(D\nabla \chi\big) = f, \qquad \chi \in \alpha(x,u), \qquad u=\chi S+R(1-S). $$Here \(u\) denotes the total methane content, \(\chi\) the dissolved methane concentration, and \(S\) the liquid saturation. The multivalued graph \(\alpha(x,u)\) describes the transition between dissolved methane and methane hydrate.
The phase constraint can be expressed through complementarity conditions
$$ \chi \leq \chi^{*}(x), \qquad S \leq 1, \qquad \big(\chi^{*}(x)-\chi\big)(1-S)=0, $$which encode the physical principle that hydrate may form only when methane reaches its maximum solubility.
In collaboration with colleagues at Oregon State University, I studied well-posedness, comparison principles, and numerical approximation for this class of models using techniques from nonlinear PDEs, monotone operator theory, convex analysis, and numerical analysis. More recently, I have become interested in connecting porous media models with reduced-order modeling, geometric data analysis, and machine learning methods for complex multiscale systems.
Adsorption Models and Non-Equilibrium Kinetic Systems
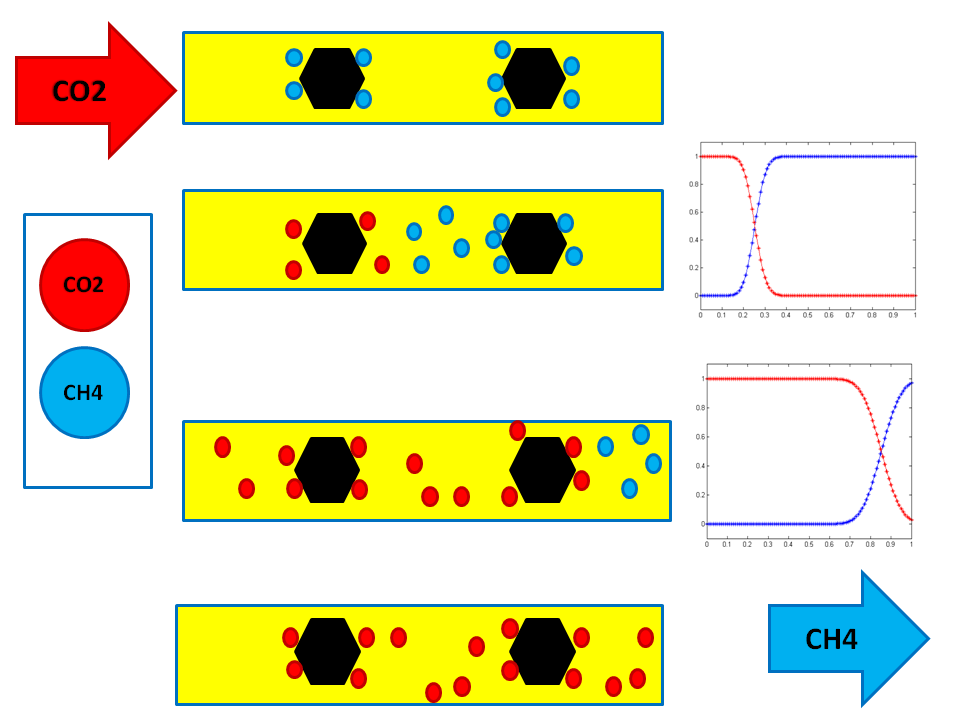
I have also worked on mathematical models for adsorption processes in porous media, motivated in part by applications such as coalbed methane recovery, contaminant transport, and multicomponent gas displacement. In these models, a chemical component may move with the fluid while also being adsorbed onto the solid matrix.
A basic non-equilibrium adsorption model couples the concentration of the mobile component, denoted by \(u\), with the adsorbed or immobile component, denoted by \(v\):
$$ (\phi u)_t + v_t + \nabla \cdot (q u) - \nabla \cdot (\phi d \nabla u) = f, $$ $$ v_t = \alpha \big(g(u)-v\big). $$Here \(\phi\) denotes porosity, \(q\) is the velocity field, \(d\) is a diffusion or dispersion coefficient, and \(\alpha>0\) is a kinetic rate parameter. The function \(g(u)\) describes the adsorption isotherm, which relates the mobile concentration to the equilibrium adsorbed amount.
In collaboration with Dr. Malgorzata Peszynska, I studied stability of numerical schemes for these non-equilibrium kinetic systems. A key idea was to work in weighted spaces where the coupled system becomes symmetric, allowing stability results for implicit, explicit, and implicit-explicit discretizations.
For example, in the linear case \(g(u)=cu\), the abstract kinetic system can be written as
$$ U' + V' + L U = F, $$ $$ V' + \alpha(V-cU)=0. $$Although the system may be nonnormal in the natural variables, a weighted inner product of the form
$$ \left\langle [U,V]^T,[\Phi,\Psi]^T \right\rangle_c = c\langle U,\Phi\rangle + \langle V,\Psi\rangle $$reveals a useful symmetric structure. This transformation makes it possible to establish strong stability of the continuous problem and of associated numerical schemes.
Earlier work also included adsorption models based on Langmuir-type isotherms. In the single-component case, one commonly uses
$$ a(u)=V_L \frac{bu}{1+bu}, $$where \(V_L\) is the Langmuir volume capacity and \(b\) is the Langmuir constant. For multicomponent adsorption, the mathematical structure becomes more delicate because thermodynamic consistency may fail for simple explicit extensions of the Langmuir model. This led to interest in implicit isotherm formulations such as the Ideal Adsorbed Solution framework.
This research connects nonlinear transport, adsorption kinetics, numerical analysis, stability theory, and porous media modeling. It also continues to inform my broader interest in reduced models and data-driven approaches for complex multiscale systems.